Please select and click on a face image to view the face swapping demo!




Target
VividFace (Ours)
Video face swapping is becoming increasingly popular across various applications, yet existing methods primarily focus on static images and struggle with video face swapping because of temporal consistency and complex scenarios. In this paper, we present the first diffusion-based framework specifically designed for video face swapping. Our approach introduces a novel image-video hybrid training framework that leverages both abundant static image data and temporal video sequences, addressing the inherent limitations of video-only training. The framework incorporates a specially designed diffusion model coupled with a VidFaceVAE that effectively processes both types of data to better maintain temporal coherence of the generated videos.
To further disentangle identity and pose features, we construct the Attribute-Identity Disentanglement Triplet (AIDT) Dataset, where each triplet has three face images, with two images sharing the same pose and two sharing the same identity. Enhanced with a comprehensive occlusion augmentation, this dataset also improves robustness against occlusions. Additionally, we integrate 3D reconstruction techniques as input conditioning to our network for handling large pose variations.
Extensive experiments demonstrate that our framework achieves superior performance in identity preservation, temporal consistency, and visual quality compared to existing methods, while requiring fewer inference steps. Our approach effectively mitigates key challenges in video face swapping, including temporal flickering, identity preservation, and robustness to occlusions and pose variations.
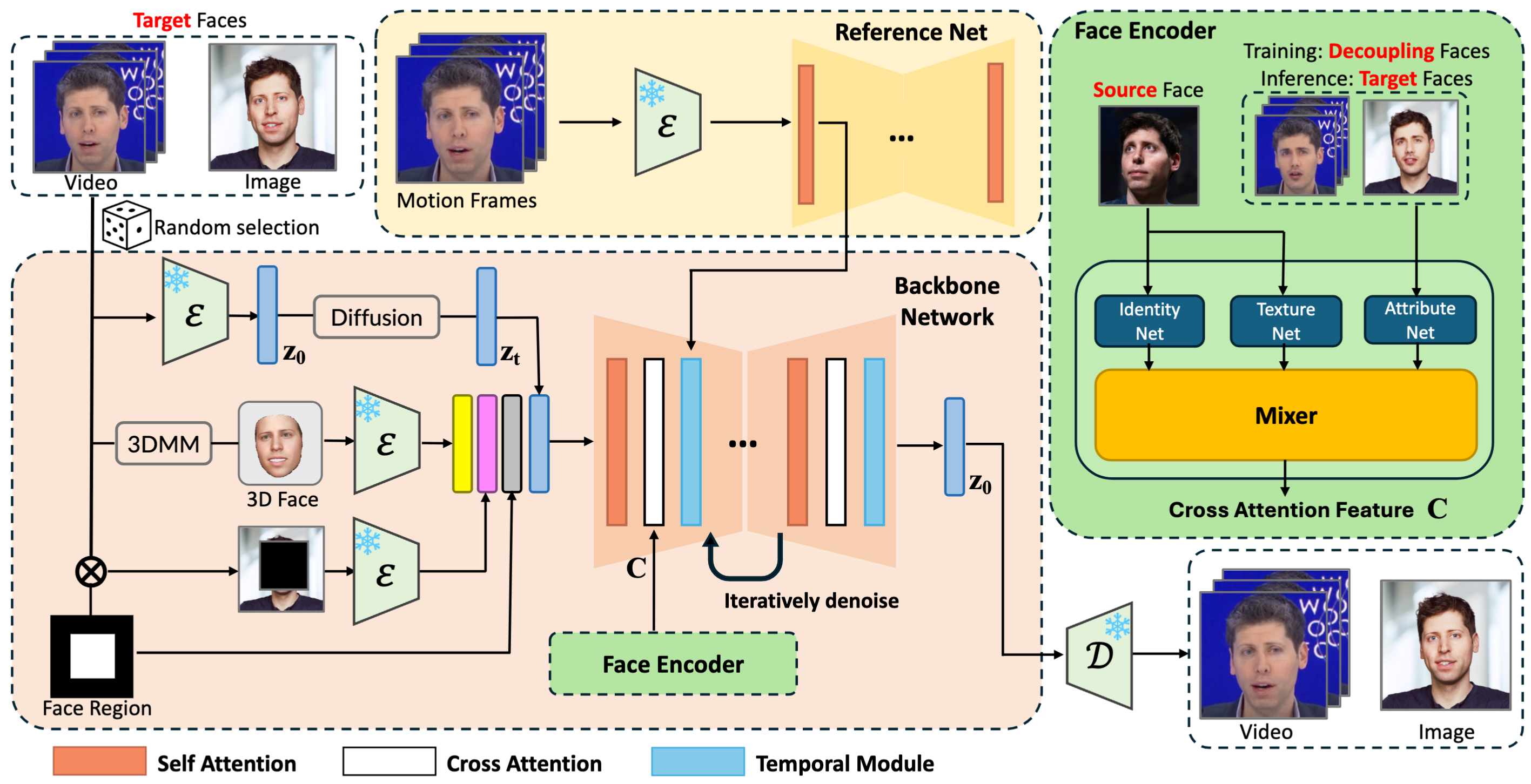
Overview of the proposed framework. During training, our framework randomly chooses static images or video sequences as the training data. In addition to the noise zt, three other types of inputs are integrated to guide the generation process: (1) a face region mask, which controls the generation of facial imagery; (2) a 3D reconstructed face, which helps guide the pose and expression, especially in cases of large pose variations; and (3) masked source images, which supply background information. These inputs are processed through the Backbone Network, which performs the denoising operation. Within the Backbone Network, we employ cross-attention and temporal attention mechanisms. The temporal attention module ensures temporal continuity and consistency across frames. Our face encoder extracts identity and texture features from the target face, as well as pose and expression details from the source face, and uses these features in cross-attention to produce realistic and high-fidelity results.
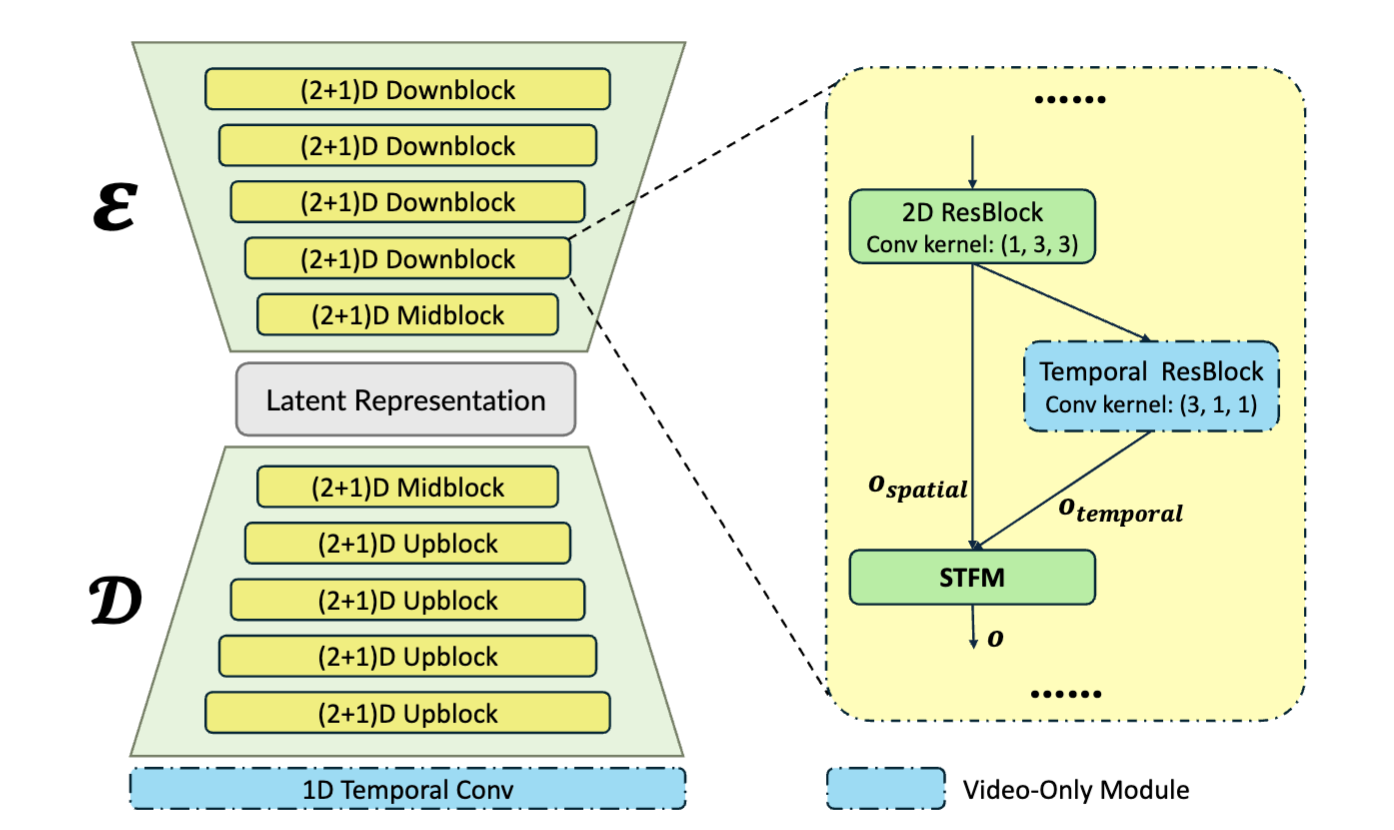
Overview of the proposed VidFaceVAE, capable of simultaneous encoding and decoding of both image and video data. Certain modules are specifically designed for video inputs, and image inputs bypass these modules as needed.

We construct triplet pairs for our AIDT (Attribute-Identity Disentanglement Triplet) dataset as shown in the figure. For video facial data, we present only the target and decoupling faces, as the source faces can be derived from any other frame within the same video clip.
The AIDT dataset enables the face encoder to disentangle and fuse distinct facial components—ID features, texture features from the source face, and attribute features from the decoupling face. This enhances generalization, especially when the source and target faces belong to different individuals during inference.
Occlusion and large pose scenarios
Note: Other methods (such as FSGAN, DiffFace, DiffSwap, and REFace) tend to produce errors and cannot reliably generate videos.

Comparison with other methods


@misc{shao2024vividfacediffusionbasedhybridframework,
title={VividFace: A Diffusion-Based Hybrid Framework for High-Fidelity Video Face Swapping},
author={Hao Shao and Shulun Wang and Yang Zhou and Guanglu Song and Dailan He and Shuo Qin and Zhuofan Zong and Bingqi Ma and Yu Liu and Hongsheng Li},
year={2024},
eprint={2412.11279},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.11279}}