|
I am an third-year PhD student in Multimedia Laboratory in the Chinese University of Hong Kong. I'm supervised by Prof. Hongsheng Li and Prof.Xiaogang Wang. Before that, I received my Master's degree from Tsinghua University in 2022, and my Bachelor degree from the University of Electronic Science and Technology of China in 2019. My research interests lie in the area of Generative models and Autonomous Driving. Specifically, I'm particularly interested in multi-modal large language model, video generation, end-to-end autonomous driving. Please email me if you have any questions or want to collaborate. I will be on the job market for 2026. Please feel free to reach out if you have openings in industry or academia. |

|
|
|

|
Aug. 2022 - , Department of Electronic Engineering, the Chinese University of Hong Kong PhD Student |

|
Sept. 2019 - Jun. 2022 , School of Software Engineering, Tsinghua University Master |

|
Sept. 2015 - Jun. 2019 , School of Software Engineering, University of Electronic Science and Technology of China Bachelor GPA: 3.98/4 |
|
|

|
We introduce a novel plug-and-play adaptation method that enables diffusion models to be conditioned on multiple reference images and the text prompt. |
|
|

|
We propose a diffusion-based framework for video face swapping, featuring hybrid training, an AIDT dataset, and 3D reconstruction for superior identity preservation and temporal consistency. |
|
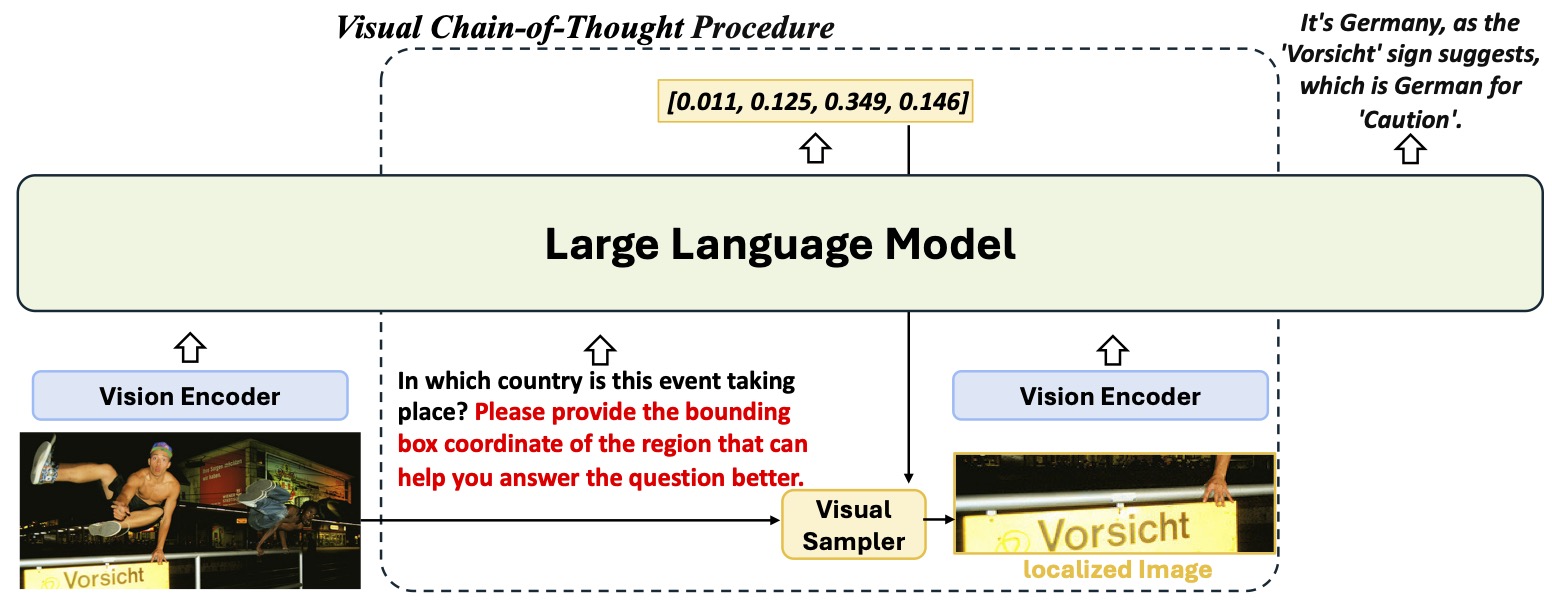
We propose Visual CoT, including a new pipeline/ dataset/ benchmark that enhances the interpretability of MLLMs by incorporating visual Chain-of-Thought reasoning, optimizing for complex visual inputs. |
|
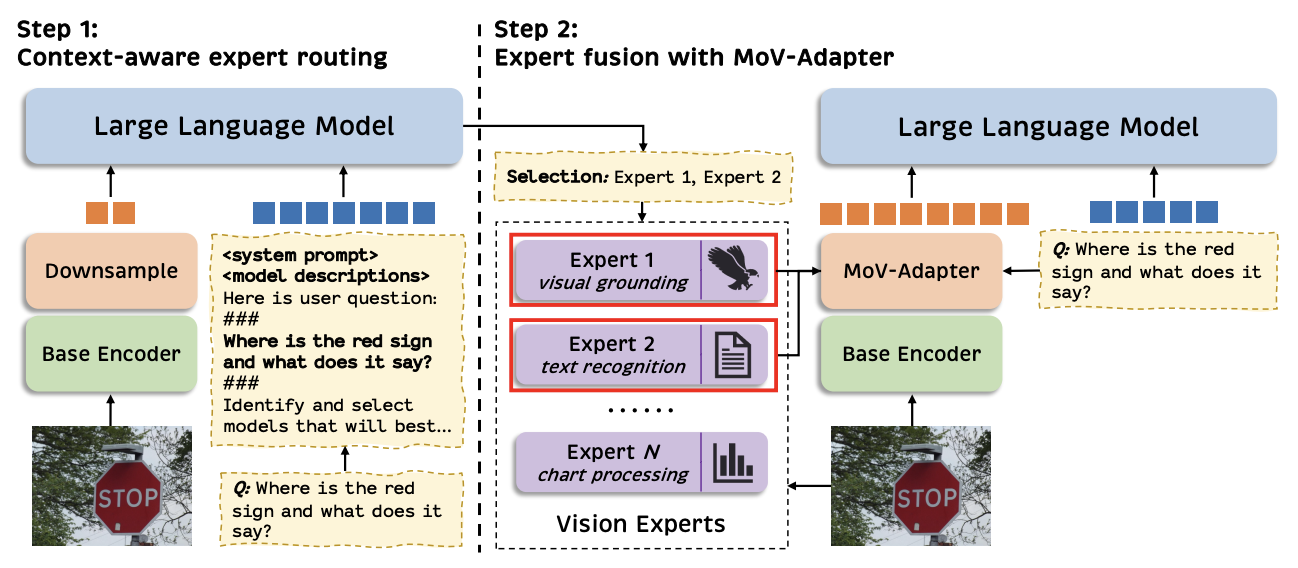
MoVA is a novel MLLM that can adaptively route and fuse multiple task-specific vision experts in a coarse-to-fine mechanism, alleviating the bias of CLIP vision encoder. |

|
We propose SmartPretrain, a general and scalable self-supervised learning framework for motion prediction, designed to be both model-agnostic and dataset-agnostic. |
|
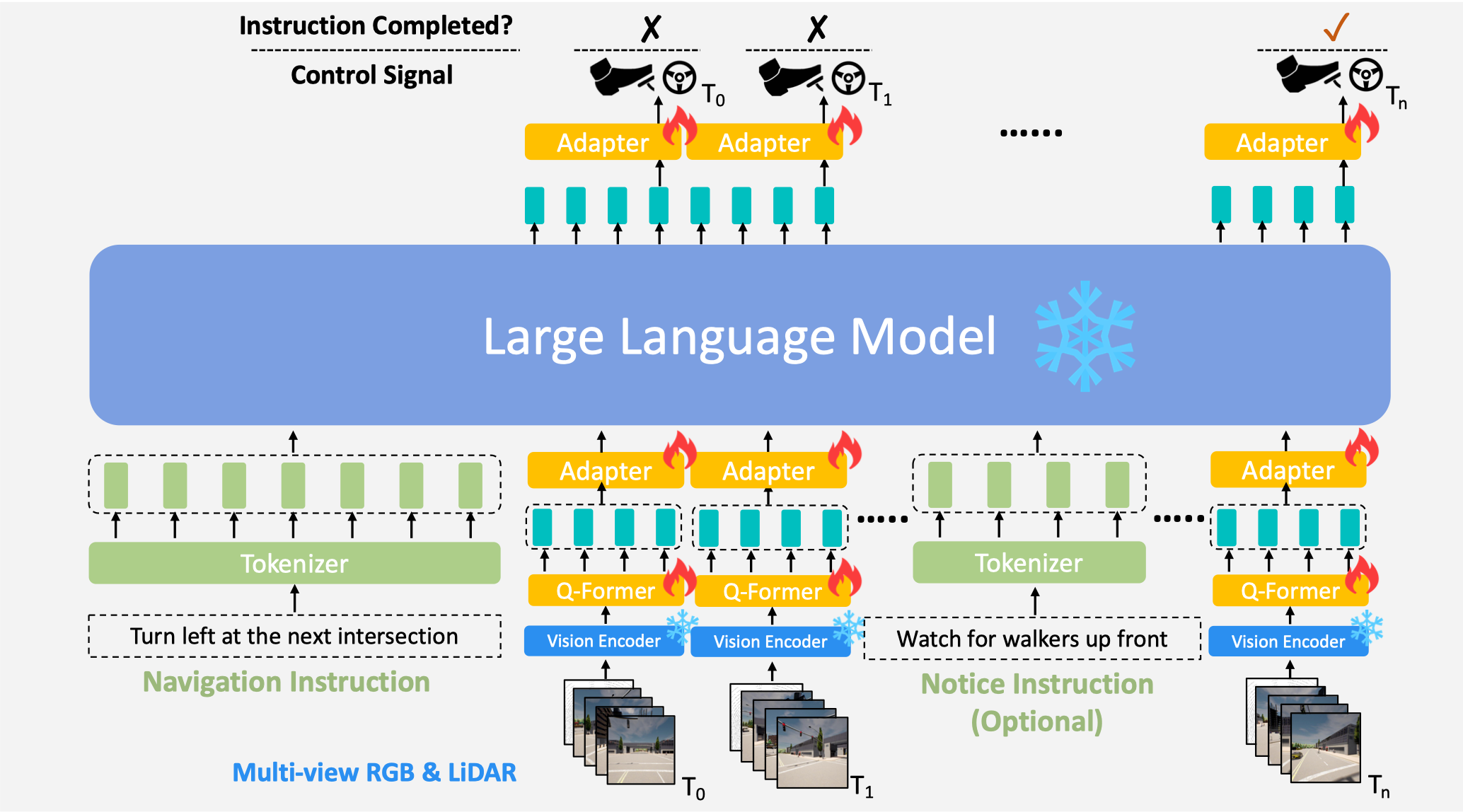
We propose a novel end-to-end, closed-loop, language-based autonomous driving framework, LMDrive, which interacts with the dynamic environment via multi-modal multi-view sensor data and natural language instructions. |
|
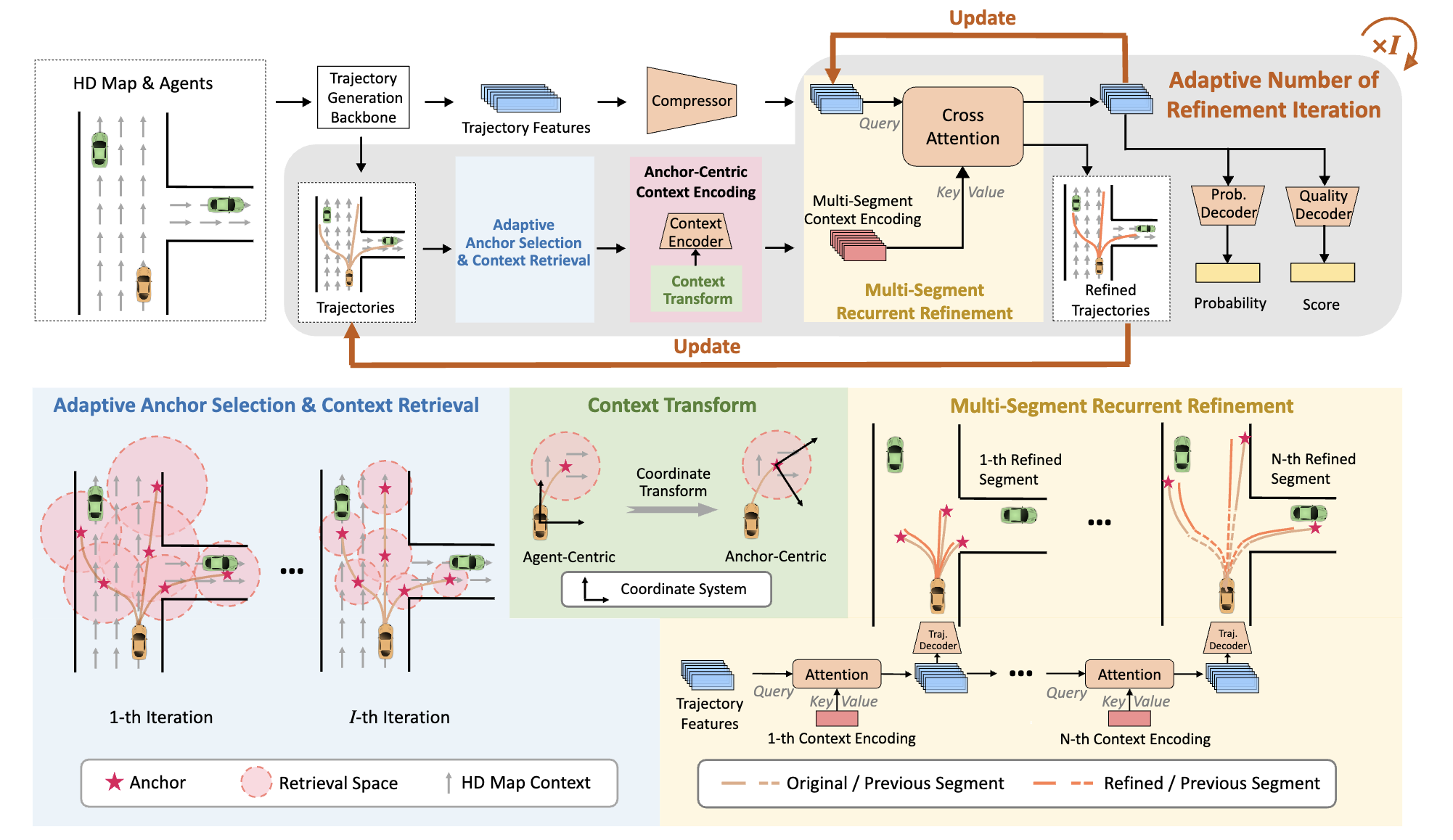
We introduce a novel scenario-adaptive refinement strategy to refine trajectory prediction with minimal additional computation. |
|
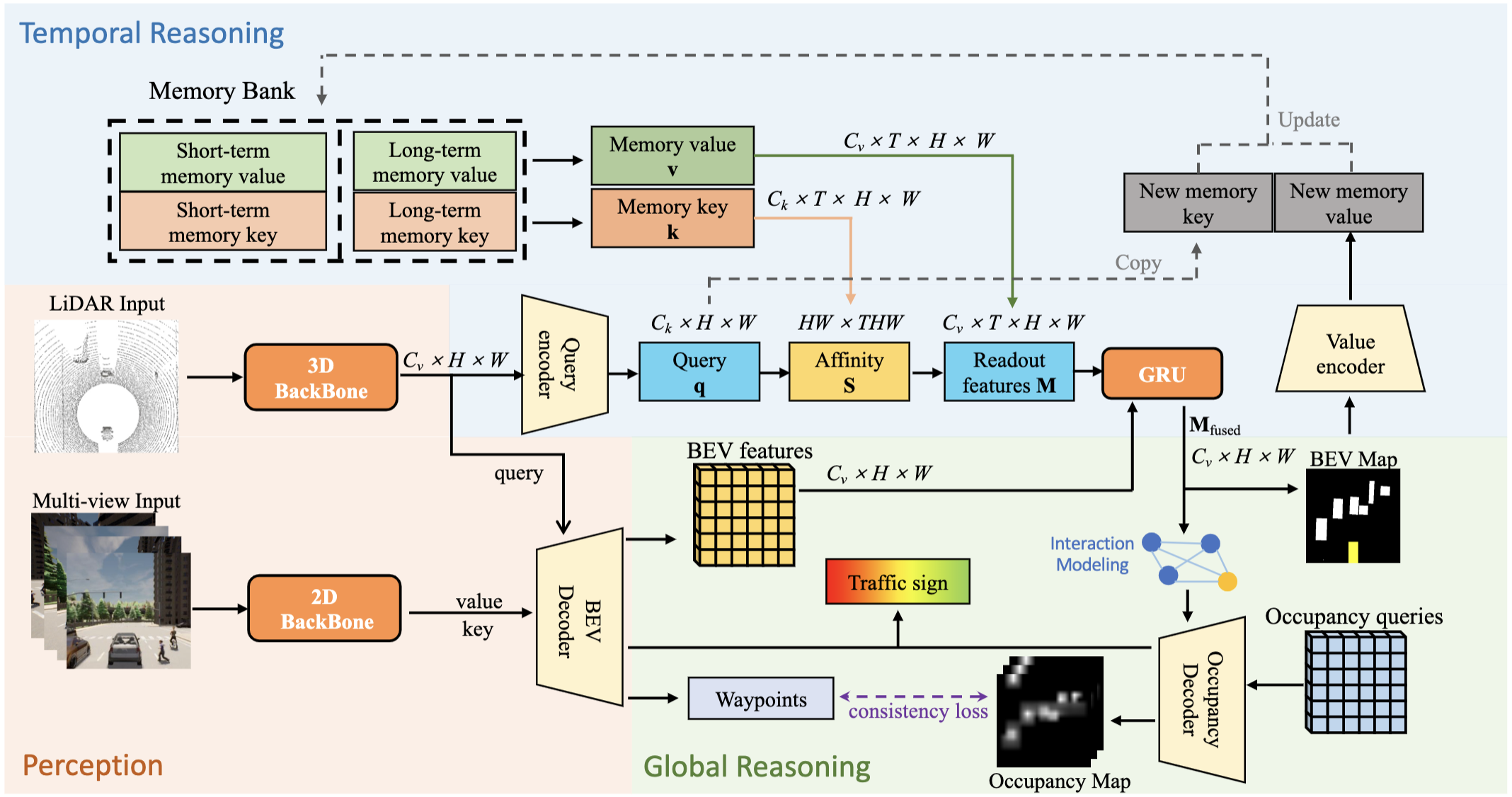
We present ReasonNet, a novel end-to-end driving framework that extensively exploits both temporal and global information of the driving scene. |
|
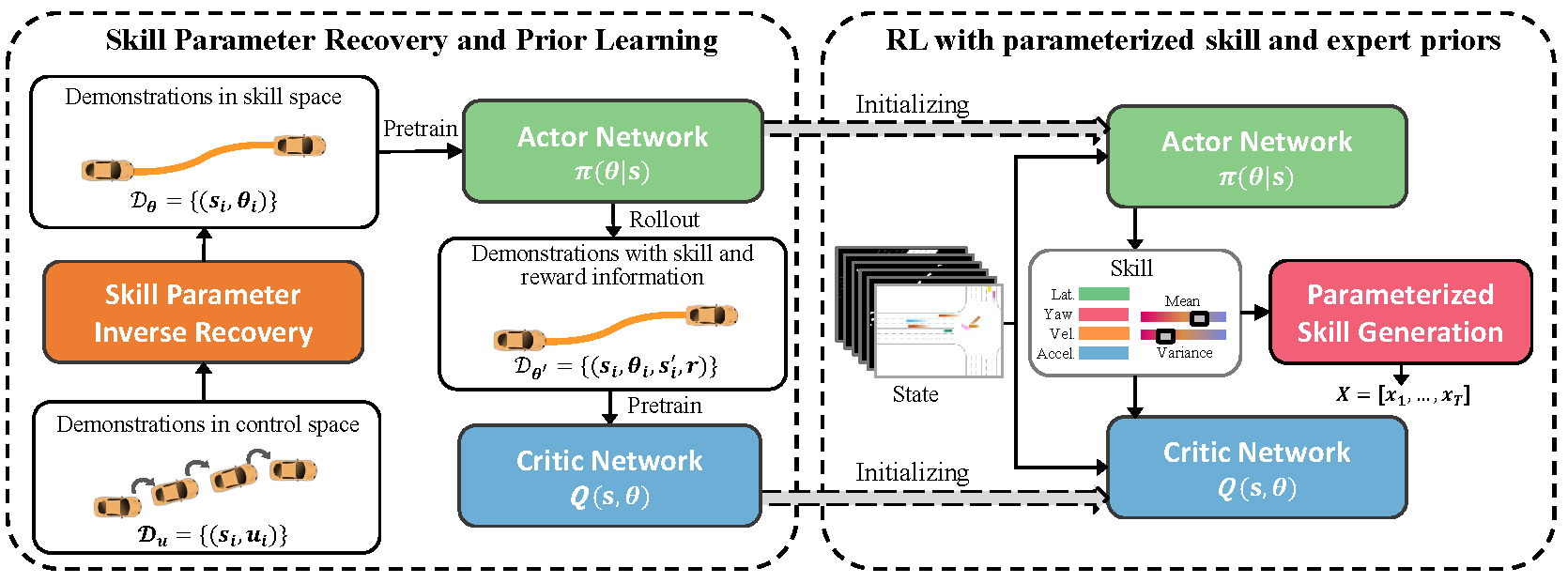
We present an efficient reinforcement learning (ASAP-RL) that simultaneously leverages parameterized motion skills and expert priors for autonomous vehicles to navigate in complex dense traffic. |
|
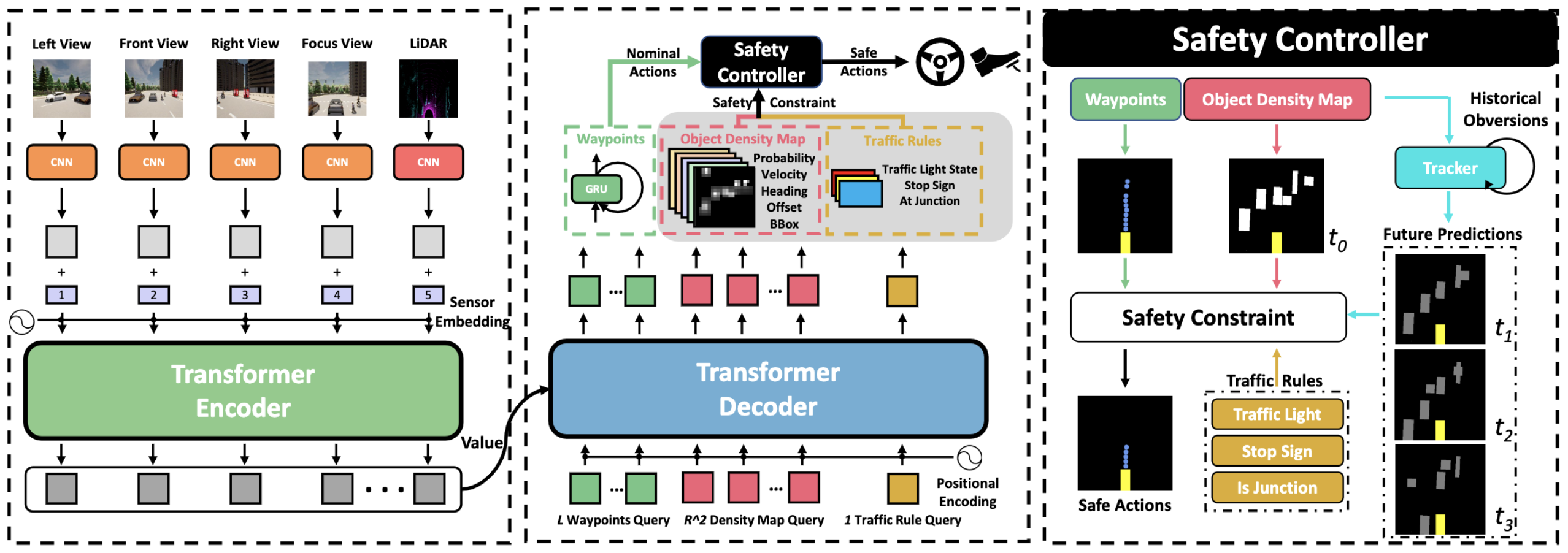
We propose a safety-enhanced autonomous driving framework to fully process and fuse information from multi-modal multi-view sensors for achieving comprehensive scene understanding and adversarial event detection. |
|
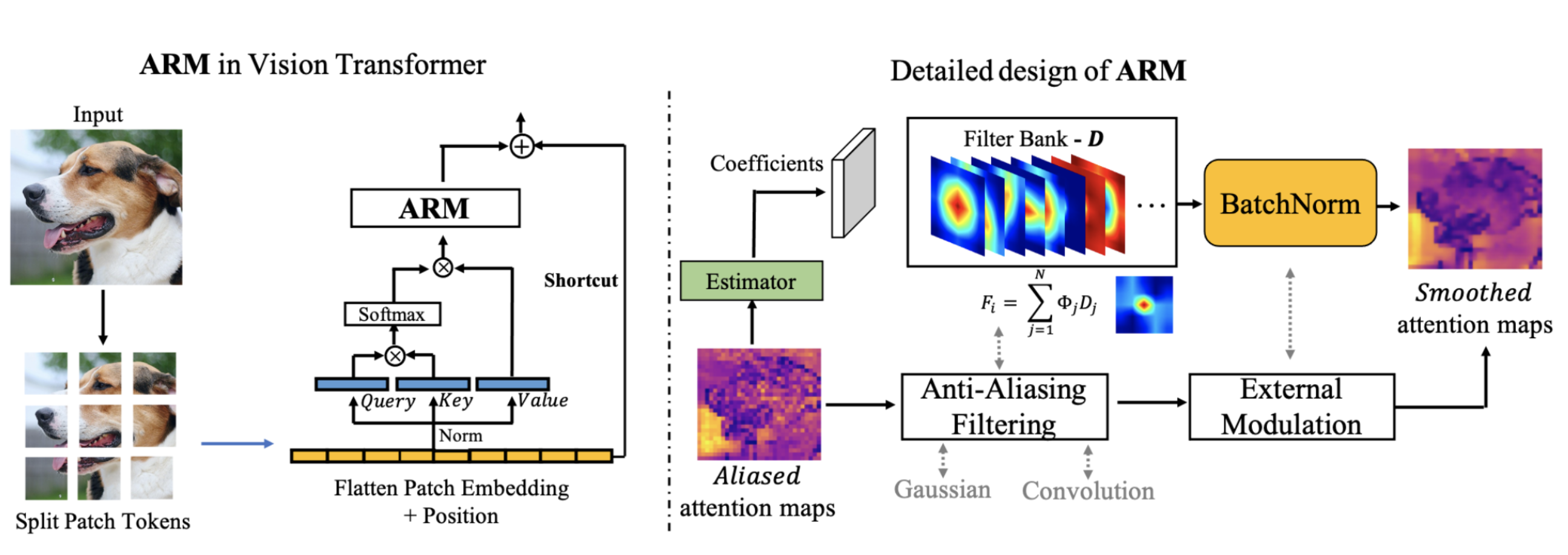
We propose a plug-and-play Aliasing-Reduction Module (ARM) to alleviate the problem of aliasing in vision transformer. |
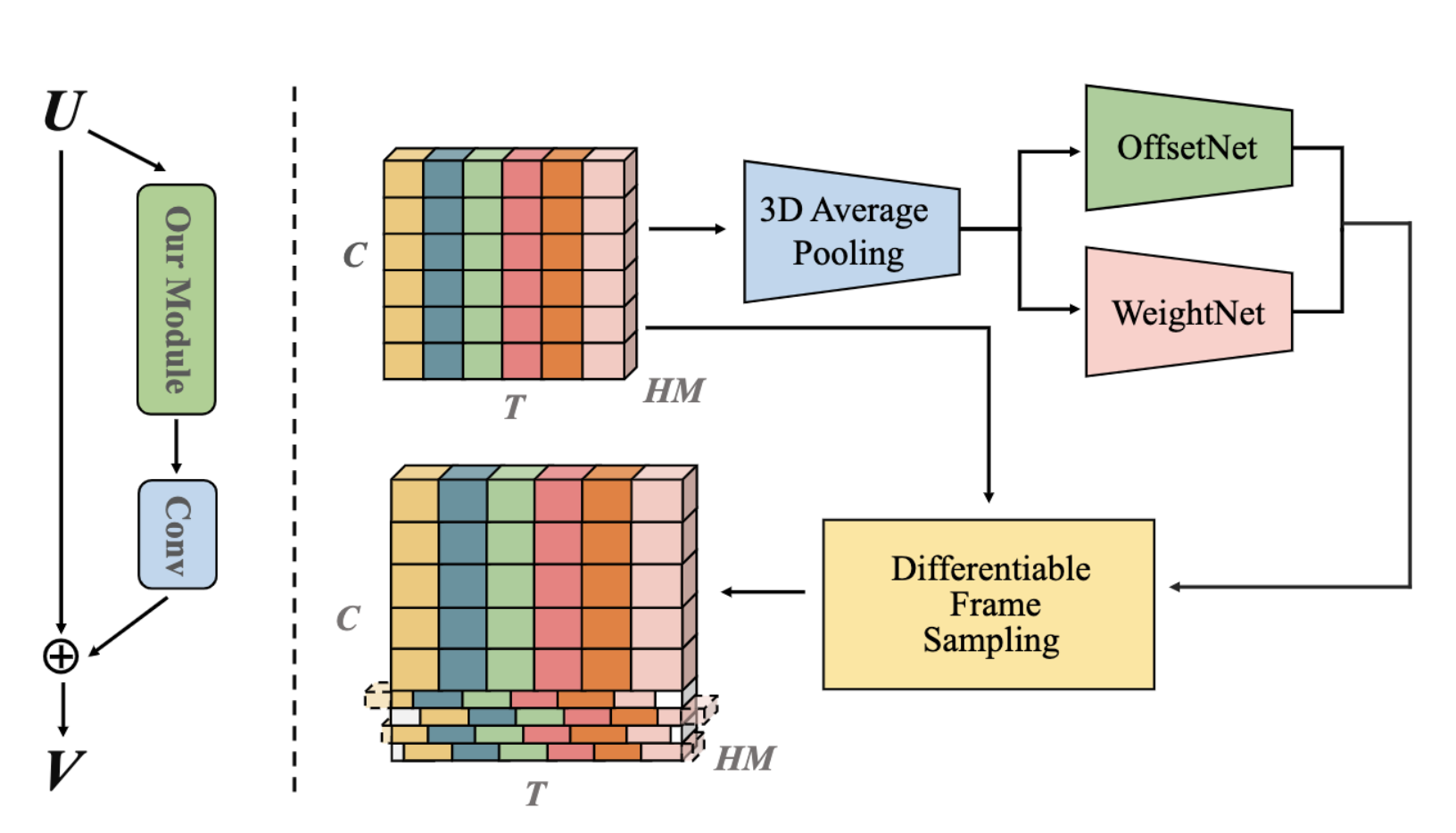
|
We present a simple yet powerful operator – temporal interlacing network (TIN). TIN fuses the two kinds of information by interlacing spatial representations from the past to the future, and vice versa. |
|
|

|
Apr 2019 - Now, XLab Researcher(intern). Beijing, China |

|
Sep 2018 - Apr 2019, Computer Vision Research intern. Shenzhen, China |

|
Jul 2017 - May 2018, Recommend System Research intern. Beijing, China |
|
|
-
Postgraduate Scholarship, the Chinese University of Hong Kong, 2023 ~ now
-
The First Prize, CARLA Autonomous Driving Challenge (Sensor track), 2022
-
The First Prize, CVPR20 ActivityNet Challenge (Kinetics700 track and AVA track), 2020
-
The First Prize, ICCV19 Multi-Moments in Time (MIT) Challenge, 2019
-
Outstanding Graduate of UESTC, 2019
-
National Scholarship, University of Electronic Science and Technology of China, 2017
|
|
-
Conference Reviewer: CVPR, ICLR, Neurips, AISTATS, ICML, ICCV
-
Journal Reviewer: Transactions on Pattern Analysis and Machine Intelligence (TPAMI), Transactions on Multimedia (TMM), Transactions on Circuits and Systems for Video Technology (TSCVT), Intelligence Vehicle (IV)
-
Teaching: ELEG5760: Machine Learning for Multimedia Applications, ENGG1130: Multivariable Calculus for Engineers, ELEG2310B: Principles of Communication Systems, ELEG5491: Introduction to Deep Learning
|
|
-
X-Temporal
, Easily implement SOTA video understanding methods with PyTorch on multiple machines and GPUs
-
Awesome End-to-End Autonomous Driving
, Paper list about end-to-end autonomous driving
-
DI-drive
, Decision Intelligence Platform for Autonomous Driving simulation
-
Fast Jieba
, Fast Chinese word segmentation library, rewriting Jieba core functions (accumulated 300K downloads)